Abgrenzung künstliche Intelligenz und Machine Learning / Deep Learning
Was ist eigentlich Künstliche Intelligenz?
Vielerorts wird vom Einsatz von künstlicher Intelligenz (kurz: KI) gesprochen, es gibt kaum mehr ein digitales Produkt, das nicht auf KI setzt. Doch stimmt das wirklich in jedem Fall? Ist überall KI drinnen, wo KI drauf steht?
Einem Artikel, der auf The Verge1 publiziert wurde, zufolge, betreiben etwa 40% aller Startup Unternehmen in Europa diesbezüglich Etikettenschwindel und schreiben sich KI auf die Fahnen, ohne tatsächlich diese Technik auf einzusetzen. Natürlich kann der Grund auch darin liegen, dass viele gar nicht so genau wissen, was künstliche Intelligenz eigentlich ist.
Artificial intelligence is the science and engineering of making computers behave in ways that, until recently, we thought required human intelligence.”
Andrew Moore 234, Former-Dean of the School of Computer Science at Carnegie Mellon University
Es geht also um Computersysteme, die ein Verhalten aufweisen, das wir bislang nur Menschen zuschrieben. Dennoch bleibt auch diese Definition sehr vage. In der Tat ist es schwer zu definieren, was eigentlich künstliche Intelligenz ist. Es ist eindeutig nicht nur jene Superpower aus Science-Fiction Drehbüchern, die über kurz oder lang auf die Idee kommt, ihre Erschaffer durch bessere Varianten zu ersetzen.
Wir definieren künstliche Intelligenz als ein Merkmal eines Computersystems, das zeigt, dass das System in der Lage ist, Entscheidungen durch bestimmte Heuristiken zielgenauer als rein per Zufall zu generieren. Darunter fallen natürlich auch Algorithmen zur Routenplanung wie der A* Algorithmus5 oder ein einfacher Optimierer für Spiele wie der MiniMax Algorithmus6.
Auch wenn die Grenzen, was wir für “Magie” halten sich laufend verändern. Vor über 50 Jahren wurden die ersten Schachcomputer entwickelt. Damals eine Kombination aus Spieltheorie und Spielstrategie. Eine Mischung, die damals nur menschlichen Spielern zugetraut wurde. Heute würde ein Schachcomputer wahrscheinlich nicht mehr als Neuheit der künstlichen Intelligenz betrachtet werden.
Die künstliche Intelligenz, die uns heute laufend begegnet zielt sehr stark auf Mensch-Maschine-Kommunikation ab. Etwa Interaktionssysteme wie Apples Siri, Google Home oder Amazon Alexa, die eine Sprachsteuerung von digitalen Prozessen ermöglichen. Es wird zu erwarten sein, dass derartige Gadgets in zehn bis zwanzig Jahren nicht mehr als intelligent betrachtet werden.
Aus diesem großen Bereich der künstlichen Intelligenz trat in den letzten Jahren das Segment Machine Learning immer stärker in den Vordergrund, die die dort eingesetzen Techniken maßgeblich von der immer größer werdenden Datenflut profitierten.
Was ist eigentlich Machine Learning?

Siehe: (https://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html)
Tom M. Mitchell (Interim Dean at the School of Computer Science at CMU, Professor and Former Chair of the Machine Learning Department at Carnegie Mellon University) formuliert die zentrale Frage, was das Kernstück der Disziplin sei so:
How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes? 7
Es geht also einerseits um die Frage, wie wir ein Computersystem bauen können, das im Stande ist, durch eigene Erfahrung zu lernen und andererseits um die Erforschung der Treiber jeglicher Lernprozesse.
Machine Learning stellt einen eigenen Zweig aus dem Bereich der künstlichen Intelligenz dar. Mittels Machine Learning Techniken werden Computersysteme erstellt, die in der Lage sind, Muster in Daten zu erkennen. Dabei ist es vordergründig egal, um welche Art von Daten es sich handelt. Ziel des Systems ist die Extraktion von Mustern, die für den Lernprozess verwendet werden können.
Angenommen wir stellen einem Machine Learning Modell eine Menge an Songs zur Verfügung, welche wir in der Vergangenheit gerne gehört haben. Das ML-Modell ist dann in der Lage, Muster in den Songs zu erkennen und diese mit bislang unbekannten Songs zu vergleichen. So kann das Modell neue Songs auswählen, die mit einer hohen Wahrscheinlichkeit meinen Geschmack treffen. Da wir die Eingangsdaten für das Modell mit einer Bezeichnung (“gefällt mir”) versehen haben, handelt es sich um ein Anwendungsbeispiel aus dem Bereich supervised learning. Derartige Systeme, die Empfehlungen für den Anwender generieren werden auch als recommender systems 8 bezeichnet.
Supervised vs. Unsupervised Learning
Wenn wir im einfachsten Fall unser ML-Modell mit Eingangsdaten laden und diese mit Bezeichnungen (labels) versehen, kann das Modell später ähnliche Inputs wieder diesen Kategorien zuordnen (bzw. anders ausgedrückt, klassifizieren). Auch bei der Klassifizierung analysiert das Modell die Eigenschaften der Inputdaten und vergleicht diese Charakteristik mit den vorhandenen Übungsbeispielen (training examples). Aufgrund dieser Analyse wählt es jene Kategorie mit der höchsten Wahrscheinlichkeit aus.
Wurde unser Modell zum Beispiel auf die Diagnose von Röntgenbildern trainiert, kann es später auch nur Röntgenbilder sinnvoll verarbeiten.
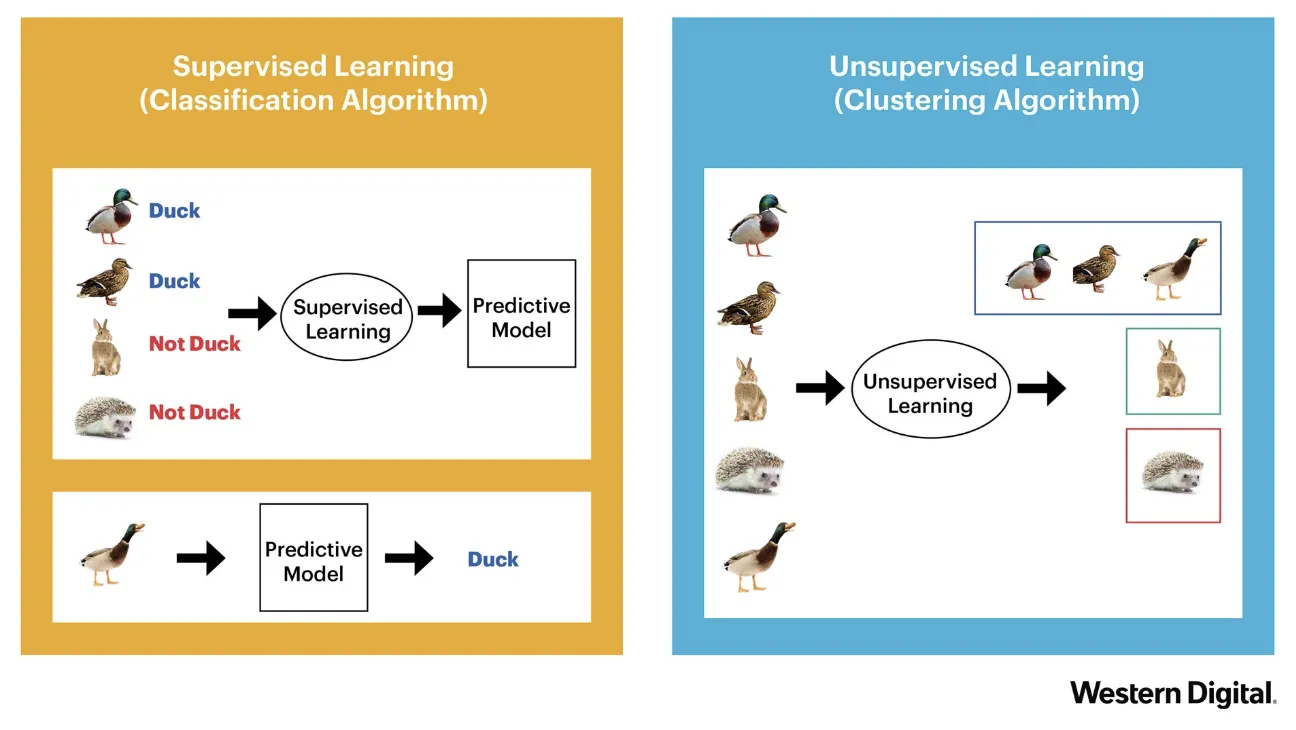
Bildquelle: Western Digital 9
Supervised learning Modelle versuchen eine Approximationsfunktion zu errechnen, die Zusammenhänge zwischen Trainingsdaten und den vergebenen Labels am besten modellieren kann.
Unsupervised Learning bedeutet hingegen, dass das Modell selbst Cluster bildet und versucht die Trainingsdaten zu gruppieren. Je nach Technik kann der Entwickler vorgeben, wieviele solcher Cluster gesucht werden sollen. Diese Modell liefern kein label sondern gruppieren lediglich die Inputmenge in Submengen.
Die dritte Kategorie ist Reinforcement Learning. Reinforcement bedeutet, dass das System von seiner Umgebung Rückmeldungen erhält und aufgrund dieser Rückmeldungen seine weiteren Handlungen plant. Nach jeder Aktion erhält das System von der Umwelt einen Stimulus (reward), der entweder positiv oder negativ hinsichtlich der geplanten Zielerreichung ist. Danach befindet sich der lernende Agent in einem neuen Status (state) und kann seinem Repertoire wieder die für ihn günstigste Handlung ziehen.
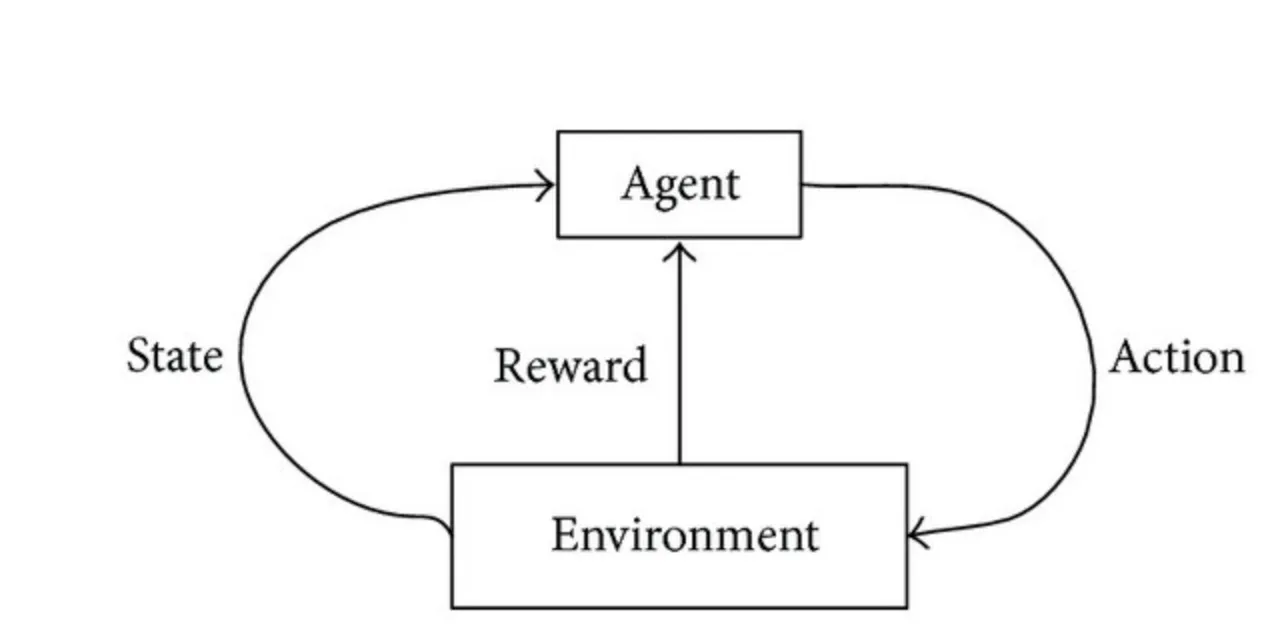
Quelle Abbildung: David Fumo10
Beim Reinforcement Learning erfolgt der Lernprozess also laufend im Sinne eines Regelkreises - diese laufende Erweiterung des Handlungsspielraums lässt sich ideal durch supervised learning Modelle ergänzen. Insbesondere episodenbasierte Spiele eignen sich hervorragend für eine Lösung mittels Reinforcement Learning.11 Der interessierte Leser sei hier an die Standardliteratur zu Reinforcement Learning von Sutton und Barto verwiesen.
Warum werden KI, MachineLearning, DeepLearning etc. laufend wechselseitig verwendet?
Der Begriff artificial intelligence wurde 1956 von einer Gruppe Wissenschafter geprägt. Seit damals durchwanderte das gesamte Forschungsgebiet der künstlichen Intelligenz mehrere Täler und Höhen. Am Anfang dieser KI-Ära stand sogleich eine Hypephase. Angespornt durch verschiedene Weltraumprogramme und dazu passende SciFi-Literatur glaubten sich einige Wissenschafter einer mensch-ähnlichen KI bereits sehr nah. Forschungsgelder waren leicht zu lukrieren.
Dieser Glaube stellte sich jedoch als Irrglaube heraus und es begann der AI-Winter. Eine Zeitspanne in der Forschungsgelder und das Interessen am Schwerpunkt sehr gering waren.
Später verwendete Unternehmen, die verschiedenen Begriffe, um sich entsprechend abzuheben bzw. zu positionieren. IBM reklamierte, dass Deep Blue (jener Schachcomputer, der erstmals Kasparow schlug) keine künstliche Intelligenz einsetze, sondern ein Supercomputer sein - wobei Deep Blue eindeutig KI-Techniken verwendete. 12 13
Danach traten andere Begriffe in Erscheinung wie Big Data, Predictive Analytics und verhalfen auch dem Bereich Machine Learning zu einem neuen Aufschwung. Im Jahr 2012 konnten durch die angehäuften Datenmengen erstmals Erfolge mithilfe neuronaler Netze erreicht werden.
Seit damals wuchsen die Datenmengen und die neuronalen Netze wurden immer größer, was den Begriff Deep Learning prägte. In der Ära von Deep Learning nahm die Entwicklung rund um neuronale Netze so richtig Fahrt auf und ermöglichte das Lösen von Aufgaben, die mittels regelbasierten Expertensystemen bislang nicht möglich waren. Beispiele dafür sind etwa Gesichtserkennung, Erkennen und Analysieren von Sprache und Text.
Fußnoten
-
https://www.theverge.com/2019/3/5/18251326/ai-startups-europe-fake-40-percent-mmc-report ↩
-
https://blogs.wsj.com/cio/2018/07/27/what-machine-learning-can-and-cannot-do/ ↩
-
youtube.com/watch?v=HH-FPH0vpVE ↩
-
https://www.forbes.com/sites/peterhigh/2017/10/30/carnegie-mellon-dean-of-computer-science-on-the-future-of-ai/#3ea38d7e2197 ↩
-
https://de.wikipedia.org/wiki/A*-Algorithmus ↩
-
https://de.wikipedia.org/wiki/Minimax-Algorithmus ↩
-
https://www.cs.cmu.edu/~tom/pubs/MachineLearning.pdf ↩
-
https://en.wikipedia.org/wiki/Recommender_system ↩
-
https://blog.westerndigital.com/machine-learning-pipeline-object-storage/ ↩
-
https://towardsdatascience.com/types-of-machine-learning-algorithms-you-should-know-953a08248861 ↩
-
https://openai.com/projects/five/ ↩
-
https://www.aaai.org/Papers/Workshops/1997/WS-97-04/WS97-04-001.pdf ↩
-
https://www.sciencedirect.com/science/article/pii/S0004370201001291 ↩